Scalability works in two directions
When talking about scalability in the context of software, it is always about being able to handle more: users, data, network traffic, etcetera.
That might not be without trade-offs: it is important to consider scalability to any size, so including smaller sizes.
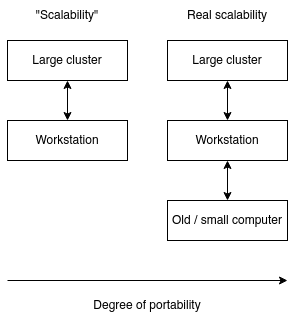
It is also important to keep a reasonable middle ground. Some projects are going too far with their minimalism (and end up externalizing complexity), and some other software is going too far in complexity. But some other projects might go too far in portability, and you end up in an ifdef hell.
Scalability, portability and low complexity should go hand in hand. If I can deploy, configure and modify your tool on Microsoft Azure or a Samsung Galaxy S2 running postmarketOS with the same ease, you’ve probably made a good tool.
Example metrics:
- Users: millions vs. singular
- Processing: many CPUs vs. single CPU
- Database: cluster vs. sqlite
- Network: 100GbE fiber vs. 100kbps GPRS
- Architecture: decoupled, many binaries vs. tightly coupled, single binary
- Security: separation of permissions per user vs. no permissions, single user can do anything
- Maintenance: team of sysadmins vs. single non-technical user
Example software:
- Linux: runs on TOP500 computers and tiny embedded systems
- Nginx: runs websites like TikTok and Wordpress, and many small personal websites
- Forgejo: codeberg.org runs on it, and many personal instances
- Mediawiki: it runs Wikipedia, and many smaller wikis